목차
- 결측치
- 이상치
- 데이터 변환 (정규화, 표준화 등..)
- 인코딩
결측치 (Missing Values)
isna(), isnull() 함수 : 데이터프레임의 각 요소가 결측치인지 여부를 확인 (동일한 기능)
df.isna() 생성 시, 각 cell값은 결측 여부에 따라 True 나 False로 반환됨
True 값은 1, False값은 0인점을 활용해 df.isna().sum() 으로 결측치의 갯수를 확인할 수 있다.
결측치 관리
dropna() : 결측치가 포함된 행이나 열을 삭제 df.dropna(axis=1)
fillna() : 결측치를 특정값으로 대체 df.fillna('없음')
interpolate() : 결측치를 주변값 기반으로 보간 df.interpolate()
특정 조건으로 처리

이상치 (Outlier)
정의 : 데이터의 일반적인 패턴에서 벗어난 값 (사람의 실수로 기입되었을 가능성이 높은 값)
1. 기술 통계 기반
- 자료의 기본 통계량을 기반으로 확인하는 방법
df['나이'].describe() 으로 나이 컬럼의 통계량 확인
2. 시각화
- 박스플롯(Box Plot) 과 히스토그램을 사용해 확인하는 방법

3. IQR (Interquartile Range)
- 1사분위수(Q1)와 3사분위수(Q3)의 차이로, 이 범위를 벗어나는 데이터를 이상치로 간주
- IQR = Q3 - Q1 // if N is in (Q1-1.5*IQR , Q3+1.5*IQR) ? (Q1 은 상위 25%, Q3는 상위 75% 자료값)

이상치 처리 방법(예시)

데이터 정규화 (Normalization)
- 데이터의 범위를 0과 1 사이로 변환하는 과정
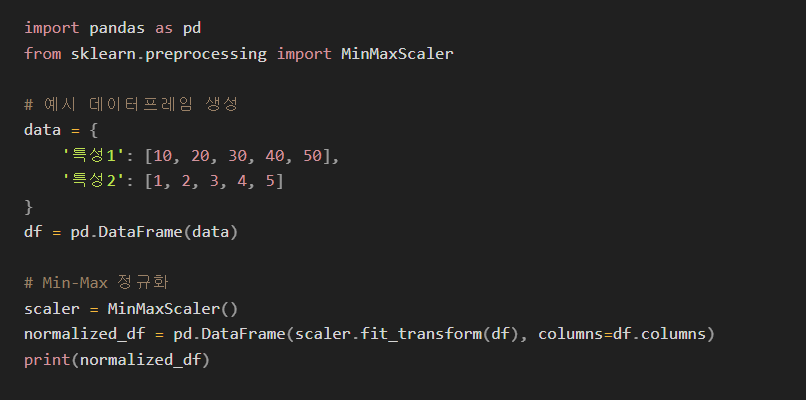
Min-Max 정규화
가장 일반적인 정규화 방법으로, 각 데이터를 최소값을 0, 최대값을 1로 변환
데이터 표준화 (Standardization)
- 데이터를 평균이 0 표준 편차가 1이 되도록 변환하는 과정
Z-점수 표준화
각 요소에서 평균을 차감하고 표준편차로 나누어 모든 데이터가 표준정규분포를 따르도록 변경

비선형 변환
- 데이터의 비정상적인 분포를 정규분포에 가깝게 만들기위해 사용
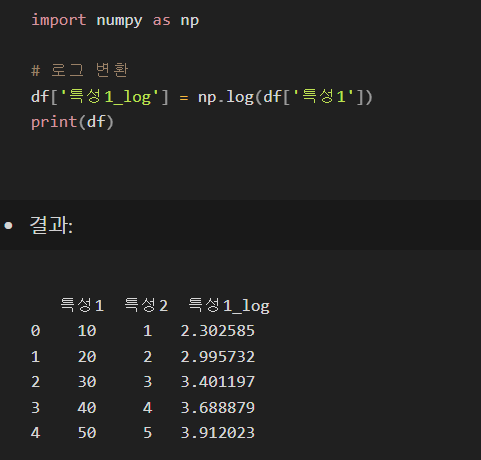
1. 로그 변환 - 데이터의 분포를 좁히는 데 유용 (지수 분포를 가진 데이터에 효과적)
2. 제곱근 변환 - 푸아송 분포를 가진 데이터에 유용한 변환

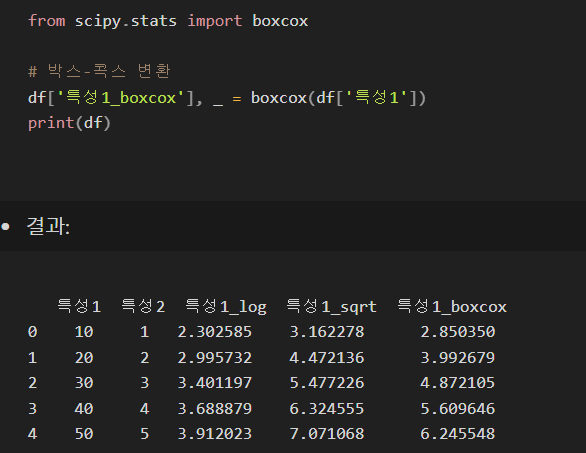
3. 박스-콕스(Box-Cox) 변환 - 양수 데이터만 사용 가능. 정규 분포에 가깝게 변환하기 위해 사용
TMI : 특정 자료분포가 일관되지 않은 이분산성이 있다고 가정할 때, 분석이 용이하도록 정규분포 형식으로 변환할 때 사용되는 변환작업

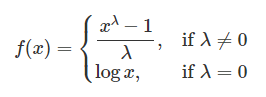
인코딩 (Encoding)
- 범주형 데이터를 수치형 데이터로 변환하는 과정.
- 많은 머신러닝 모델은 수치형 데이터만 처리가 가능해서, 범주형 데이터를 인코딩하는것이 필수적
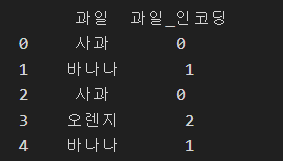
1. 레이블 인코딩 (Label Encoding)
- 특정 컬럼의 그룹에 라벨(인덱싱)을 붙히는 개념
- 범주형 데이터에 순서가 있을 때 유용

2. 원-핫 인코딩 (One-Hot Encoding)
- 각 범주를 이진 벡터로 변환
- 각 범주는 고유한 열을 가지며, 해당하는 열에는 1, 나머지 열에는 0이 할당
- 범주형 데이터에 순서가 없을 때 (독립적으로 처리할 때) 유용

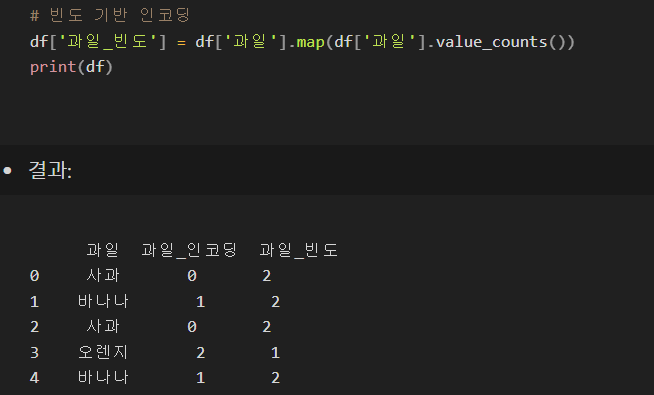
3. 차원 축소 인코딩 (Count or Frequency Encoding)
- 각 범주를 데이터셋 내에서의 출현 빈도로 인코딩
- 범주형 데이터가 많을 때 유용
4. 순서형 인코딩 (Ordinal Encoding)
- 등급 나누는 인코딩 방식

5. 임베딩 (Embedding)
- 딥러닝에서 주로 사용
- 범주형 데이터를 벡터 공간에 매핑하여 변환 (고차원 범주 데이터에 유용)
- 원-핫 인코딩에 비해 차원 축소, 메모리 절약 효과
- 범주 간의 내재된 관계 학습 가능
>> 주로 텍스트 데이터에서 단어를 벡터로 변환할 때 사용되며, Keras 등의 라이브러리에서 쉽게 구현 가능
-------------------------------------------------------------------------------
<코드카타 문제풀이 TIL>
- 리스트 형태로 저장된 자료를 반복문으로 다룰때 enumerate를 활용하면 인덱스와 자료값을 동시에 불러올 수 있어 편리하다.
