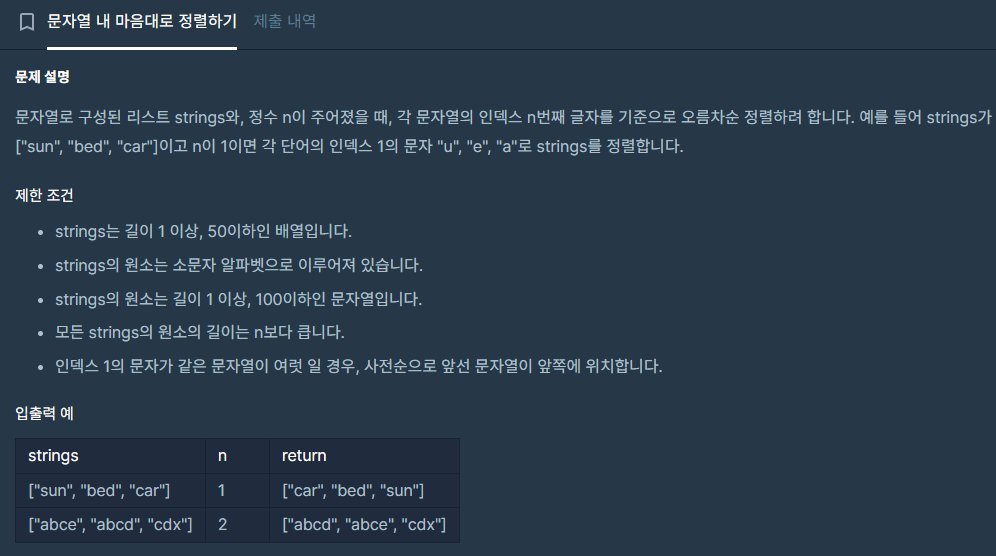
기본 정렬 sort에서 특정 조건을 만족시켜야 한다. (문자열의 n번째 인덱스를 기준으로 정렬)
또한, 문자열의 n번째 인덱스값이 동일하면 전체 단어의 오름차순으로 정렬해야 한다.
따라서, strings.sort() 를 먼저 진행한 후, 람다를 사용해 strings.sort(key=lambda x : x[n]) 으로 재차 정렬한다.
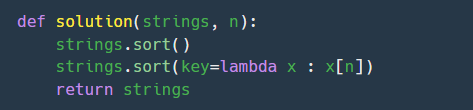
리스트 정렬 시 람다사용 예시

TMI : 람다 함수 (이름을 가지지 않는 익명 함수)


백준 2908번 : 문자열 뒤집기
string[::-1] 사용 : 슬라이싱에서 [시작:끝:스텝] 형식을 사용하며, -1은 문자열을 거꾸로 하나씩 가져오는 방식
너비 우선 탐색 (BFS, Breadth-First Search)
- 시작 노드에서 가까운 노드부터 차례대로 탐색하는 방식
- 한 레벨의 모든 노드를 먼저 탐색한 후, 그다음 레벨의 노드를 탐색
알고리즘 개념
- 큐(Queue) 자료구조를 사용하여 구현
- 먼저 방문한 노드를 큐에 넣고, 큐에서 차례대로 꺼내면서 해당 노드와 연결된 노드를 다시 큐에 넣는다
BFS 동작 예시
- 시작 노드를 큐에 넣음.
- 큐에서 노드를 하나씩 꺼내어 방문.
- 그 노드와 인접한 모든 노드를 큐에 넣음.
- 큐가 빌 때까지 2~3 과정을 반복.
BFS 특징
- 모든 노드를 층별로 탐색.
- 최단 경로 탐색에 적합.
- 시간이 오래 걸릴 수 있으므로 노드가 많은 그래프에서 비효율적

깊이 우선 탐색 (DFS, Depth-First Search)
그래프의 한 경로를 끝까지 탐색하고, 막다른 길에 도달하면 뒤로 돌아와 다른 경로를 탐색하는 방식
알고리즘 개념
- 스택(Stack) 자료구조나 재귀 호출을 사용하여 구현
- 한 경로를 끝까지 탐색한 후, 다른 경로를 탐색
DFS 동작 예시
- 시작 노드부터 방문하며, 방문할 수 있는 깊이까지 탐색.
- 더 이상 갈 곳이 없으면 이전 노드로 돌아옴.
- 모든 경로를 탐색할 때까지 반복.
DFS 특징:
- 모든 노드를 한 경로를 깊게 탐색.
- 재귀적으로 구현 가능.
- 경로가 긴 경우, 메모리 사용량이 많아질 수 있음.
- 전체 경로를 탐색해야 할 때 적합.

백준 1260번 : 그래프 탐색
문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
풀이)
1. 주어진 노드 개수를 토대로 각 노드에 인덱싱 부여 (1~N)
2. 간선 정보를 토대로 각 노드별 인접한 노드 리스트 생성 (양방향)
3. 리스트 sort (오름차순) 후 dictionary 형태로 저장
4. DFS, BFS 함수 생성 후 각 결과값 출력
------------------------------------------------------------------------------------------------------------------
데이터프레임 실습

Primary Key의 특징:
- 유일성: 각 행(레코드)에 대해 중복되지 않는 값이어야 합니다. 즉, primary key가 같은 두 행은 존재할 수 없습니다.
- 비어 있지 않음: primary key 열에는 **NULL(결측치)**가 없어야 합니다. 모든 행이 고유한 값을 가져야 하므로 비어 있으면 안 됩니다.


>> 해당 컬럼값들의 변수타입을 object 에서 datetime64 타입으로 변경